SanMaxのMicron製ネイティブ2666メモリをRYZENでどこまでOCできるか試してみました。
メモリについての記事はこちらを参照

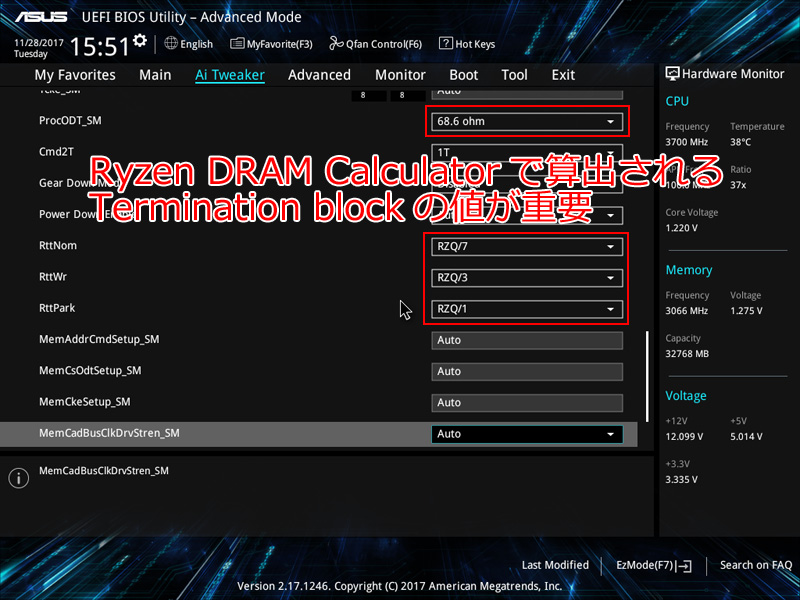
メモリOCの要 ProcODTとRTT
以前からメモリOCにはProcODTの値が重要というのは知っていたのですが、RTT値の意味、最適値が不明なため手付かずでした。しかしRyzen DRAM Calculatorのお陰で目安がわかり、ワンランク上のOCが可能になります。
実際、B350M-AのRTT/Autoでは2933が限界でしたが、RTTを最適化することで3066で動作可能になりました。この差は大きいです。
DDR4 2666と3066のCL値
2666と3066のCL設定は以下の通り。レイテンシが緩んでいるように見えますが、2666CL14=14/1330.2=10.52ns、3066CL16=16/1529.7=10.46nsと僅かに詰められました。

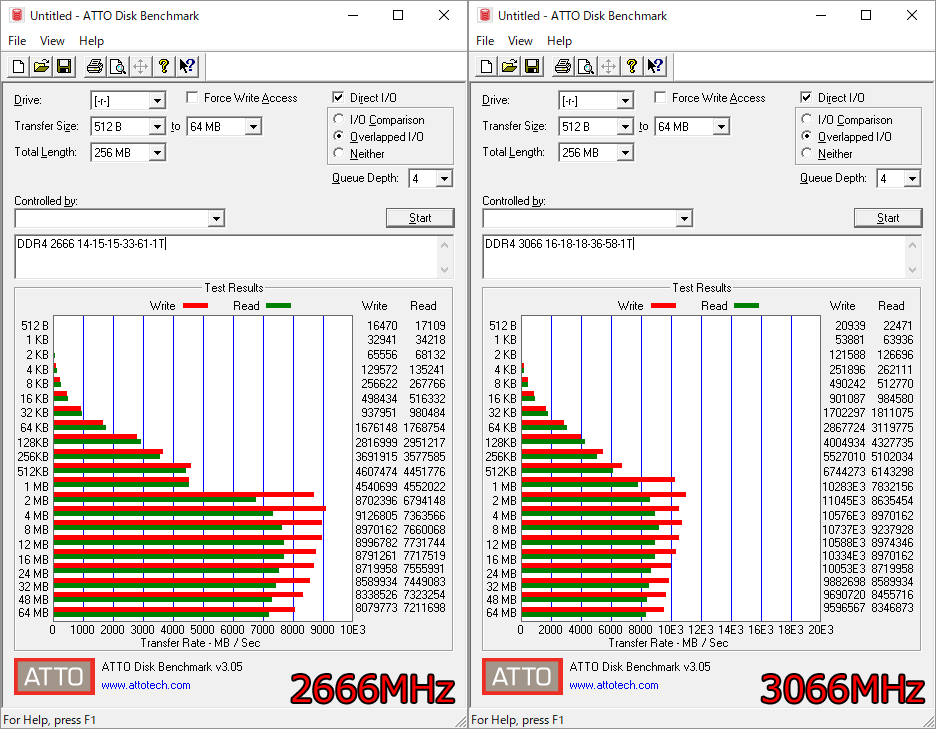
DDR4 2666と3066のメモリ速度比較
32GBのうち12GBをRADEON RAMDisk STANDARDでRamdisk化しATTOで計測します。
クロック差がそのまま速度に影響し、全域で約15%の速度が上昇していることがわかります。
MaxxMEMの値は誤差程度。一部下がっているものもあります。

AIDA64の比較。こちらも約15%の向上です。
| AIDA64 | 2666 | 3066 |
|---|---|---|
| memory read | 40882MB/s | 47226MB/s |
| memory write | 39802MB/s | 46877MB/s |
| memory copy | 39816MB/s | 45724MB/s |
| latency | 82.4ns | 77.4ns |
スレッド数ごとにアクセス速度を測定できるram_speedを試してみます。
githubのはソースコードですが作者のブログからWindows用の実行ファイルを入手することができるので、利用させてもらいます。
■rigayaの日記兼メモ帳 Ryzen7 1700のメモリ速度 (修正・追記)
http://rigaya34589.blog135.fc2.com/blog-entry-914.html
メモリ帯域(read)の比較。列の1~8は利用するスレッド数で3/5/6/7は省略。RYZENはL3キャッシュを搭載しているので、32MB~128MBがメモリの帯域です。2666→3066の上昇分、リニアにメモリ速度も上昇していることがわかります。
| 2666 | 3066 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| read | 1 | 2 | 4 | 8 | read | 1 | 2 | 4 | 8 |
| 2 KB | 110.4 | 220.8 | 441.7 | 883.4 | 2 KB | 110.4 | 220.8 | 441.7 | 883.4 |
| 4 KB | 110.8 | 220.8 | 441.7 | 883.4 | 4 KB | 110.8 | 220.8 | 441.7 | 883.4 |
| 8 KB | 106.3 | 221.6 | 441.7 | 782.0 | 8 KB | 101.1 | 221.6 | 441.7 | 883.4 |
| 16 KB | 108.5 | 212.5 | 443.3 | 883.4 | 16 KB | 108.5 | 212.5 | 443.3 | 870.8 |
| 32 KB | 104.3 | 217.0 | 425.1 | 886.5 | 32 KB | 104.3 | 217.0 | 425.1 | 886.5 |
| 64 KB | 86.5 | 210.3 | 434.0 | 848.0 | 64 KB | 85.0 | 208.5 | 434.0 | 839.8 |
| 128 KB | 86.9 | 170.1 | 420.6 | 868.1 | 128 KB | 86.9 | 170.1 | 417.1 | 868.1 |
| 256 KB | 86.8 | 173.7 | 340.2 | 843.0 | 256 KB | 86.8 | 173.7 | 340.2 | 835.9 |
| 512 KB | 83.4 | 173.6 | 347.4 | 681.8 | 512 KB | 85.4 | 173.6 | 347.4 | 680.4 |
| 1MB | 69.8 | 168.8 | 345.3 | 693.2 | 1MB | 69.8 | 145.4 | 345.3 | 694.9 |
| 2MB | 69.8 | 124.7 | 305.6 | 692.6 | 2MB | 69.8 | 130.2 | 308.0 | 692.6 |
| 4MB | 69.8 | 139.5 | 191.4 | 632.6 | 4MB | 69.8 | 122.1 | 189.0 | 600.6 |
| 8MB | 32.7 | 84.5 | 186.1 | 389.3 | 8MB | 33.1 | 86.8 | 189.5 | 378.0 |
| 16MB | 21.9 | 34.7 | 33.6 | 377.8 | 16MB | 23.0 | 38.4 | 39.1 | 372.3 |
| 32MB | 21.9 | 35.1 | 33.7 | 36.5 | 32MB | 23.0 | 37.5 | 39.0 | 42.8 |
| 64MB | 21.9 | 34.7 | 33.7 | 36.3 | 64MB | 23.0 | 37.6 | 39.0 | 42.0 |
| 128MB | 21.9 | 34.8 | 33.7 | 36.2 | 128MB | 23.0 | 37.5 | 39.0 | 42.0 |
最後にメモリ帯域(write)の比較。こちらはreadに比べるとだいぶ低めですが、13%程度の速度向上を確認できます。
| 2666 | 3066 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| write | 1 | 2 | 4 | 8 | write | 1 | 2 | 4 | 8 |
| 2 KB | 55.2 | 110.4 | 220.8 | 441.7 | 2 KB | 55.2 | 110.4 | 220.8 | 441.7 |
| 4 KB | 55.4 | 110.4 | 220.8 | 441.7 | 4 KB | 55.4 | 110.4 | 220.8 | 441.7 |
| 8 KB | 55.4 | 110.8 | 220.8 | 441.7 | 8 KB | 55.4 | 110.0 | 220.8 | 441.7 |
| 16 KB | 55.8 | 95.5 | 221.2 | 441.7 | 16 KB | 55.8 | 96.8 | 176.4 | 441.7 |
| 32 KB | 55.6 | 102.3 | 164.1 | 442.5 | 32 KB | 55.6 | 102.1 | 179.5 | 356.7 |
| 64 KB | 53.6 | 99.7 | 186.3 | 344.7 | 64 KB | 54.7 | 102.5 | 197.0 | 338.5 |
| 128 KB | 53.6 | 105.0 | 192.0 | 373.7 | 128 KB | 53.6 | 106.1 | 205.3 | 380.8 |
| 256 KB | 54.3 | 105.9 | 207.9 | 396.1 | 256 KB | 54.3 | 105.9 | 207.9 | 375.6 |
| 512 KB | 54.3 | 108.5 | 213.1 | 415.5 | 512 KB | 54.3 | 108.5 | 214.4 | 415.9 |
| 1MB | 54.3 | 107.0 | 214.1 | 421.3 | 1MB | 54.3 | 108.5 | 217.0 | 421.3 |
| 2MB | 54.3 | 108.5 | 211.1 | 429.7 | 2MB | 54.3 | 105.6 | 211.1 | 432.6 |
| 4MB | 53.5 | 108.5 | 191.7 | 423.8 | 4MB | 53.5 | 107.0 | 211.1 | 422.4 |
| 8MB | 24.7 | 75.5 | 182.8 | 380.0 | 8MB | 25.3 | 76.7 | 186.0 | 380.0 |
| 16MB | 12.5 | 16.8 | 15.6 | 354.5 | 16MB | 12.2 | 17.8 | 17.6 | 351.3 |
| 32MB | 12.5 | 16.6 | 15.7 | 15.7 | 32MB | 12.1 | 17.5 | 17.6 | 17.8 |
| 64MB | 12.4 | 16.5 | 15.7 | 15.5 | 64MB | 12.2 | 17.5 | 17.7 | 17.6 |
| 128MB | 12.4 | 16.3 | 15.7 | 15.4 | 128MB | 12.2 | 17.4 | 17.6 | 17.5 |
DDR4 2666と3066のアプリ比較
CineBenchR15はSingleは変わらずMultiが向上。これはメモリ速度に比例してinfinity fabricの速度も向上したから?

FF14ベンチはメモリ速度がFPSに影響するらしいので試してみたのですが・・・測定誤差程度にしか違いがありません。そもそもRX560では力不足なのかも?

ということで描写負荷を下げてみると僅かにスコアアップしましたがそれでも測定誤差レベルです。GPUのボトルネックが原因なのか、RYZENのメモリ管理が優秀なのか特定できないので、この検証は失敗です。
HandbrakeでフルHDの動画を再エンコードした時のfpsを比較してみました。
x264 Preset:Very Slowだとまったく変わりませんが、x264 Preset:Mediumの場合は6%程度高速化できています。エンコードのパラメータにもよりますがそれなりに効果は期待できそうです。
| handbrake 10.3 | 2666 | 3066 |
|---|---|---|
| FullHD→FullHD x264 Preset:Very Slow |
29.7fps | 29.7fps |
| preset Android Tablet x264 Preset:Medium |
146.4fps | 155.6fps |
SMD4-U32G48M-26V-D総評
メモリの2666→3066化に約4万円の出費と考えると費用対効果は微妙ですが、安心のSanMax製メモリで自己責任とは言えOCもかなりイケる16GBx2枚と考えればむしろ安いかもしれません。それにmini-itx化の準備もできました。中々良い買い物だったと思います。

